Which AIs Officially Support LLMs.txt or LLM.txt?
Written by ![]()

Regardless of your stance on whether LLMs and other AI systems are good or not, there's one reality of their operation that desperately needs control: scraping.
There are many thousands of bots that are constantly crawling the internet. Some of them are beneficial, like Google's spiders crawling and indexing your site for the search engine. Other search engines have theirs as well: the Bing bots, the Yahoo bots, the DuckDuckGo bots, and so on.
There are also malicious bots. Bots that scrape sites so they can spin up replicas for phishing. Bots that scrape and steal user information. Bots that seek out forms to submit spam to, in comments or email contact forms.
Today, Akamai estimates that 42% of internet traffic is bots, and 65% of bot traffic can be characterized as malicious.
Where does AI fit into this?
AIs like ChatGPT require immense amounts of data to train on. One of the current ongoing debates (ethical, legal, and otherwise) about it is whether or not they need to have the right to access that data.
For now, companies like OpenAI have taken a "just do it and ask forgiveness later" approach. Their legions of bots are scraping every corner of the internet. Unfortunately, unlike something like Google's bots, which are optimized to be as low-impact as possible, you have stories like this one: a website with servers configured to handle 200,000 simultaneous connections without a problem, having 100% of that capacity hoovered up by the AI scraping bots. Or these, where barely available archives are repeatedly brought down by the baleful eye of the scraper.
I've been seeing a bunch of solutions to this problem. Some are meant more for poisoning the AIs, like parallel sites that throw garbage pages in an infinite loop at bots detected to be coming from AIs. Others are defensive, like just cutting off the bot IPs that hammer the site, though the AI bots seem to spin up more sources to get around these.
Some people have taken an interesting path.
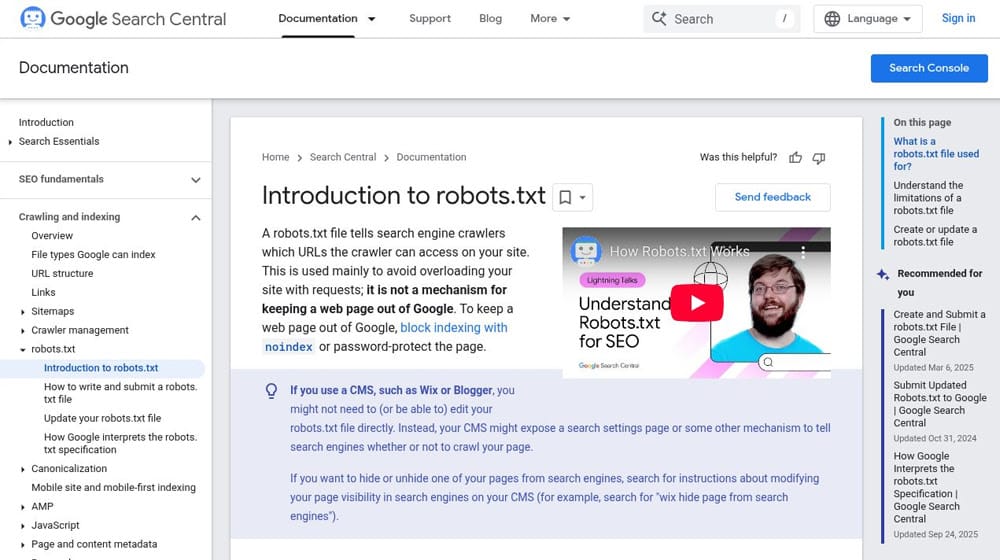
See, modern bots (the good ones anyway) check for a specific file on a website before they do anything else. This file, robots.txt, is useful for blocking bots you don't like, or for blocking bots you do like from crawling pages like system pages they shouldn't be on. There are tools to generate and validate robots.txt files everywhere, including mine.
What if there were a similar file to manage the AI scraping bots?
That's the thought that Jeremy Howard had, and he proposed LLMs.txt as an AI-specific version of robots.txt to guide and control the bots. Others, like Rob Garner, have picked up and written about the concept, and even big-name plugins like Yoast have added the ability to use one to their systems.
What is LLMs.txt?
Before I get too deep into this discussion, I need to draw a line in the sand and clarify something.
Robots.txt and LLMs.txt are actually quite different in how they work and how they attempt to solve their problems.
Robots.txt is basically a list of URLs and a directive telling bots whether they can or can't access the pages. It's a good way to tell good bots to stay off of pages they don't need to know about, like system pages and administrative pages.
LLMs.txt takes a different approach.
The concept behind LLMs.txt is to have a file that serves up your site on a silver platter for AI consumption. It's not guidance for how to control the AI scraper bots; it's just a way to give them what they want without them slamming every page on your site hundreds of times and loading every byte they can get their hands on.
It's kind of like bait and a distraction. "Here, have this succulent slice of meat, just don't go into the kitchen."
This stems from the source of the concept, primarily. The people proposing LLMs.txt are generally AI proponents, which means they want the AIs to succeed at scraping anything and everything. But they recognize that the server hammering is bad and that it could get them in trouble down the line. So, they propose this solution.
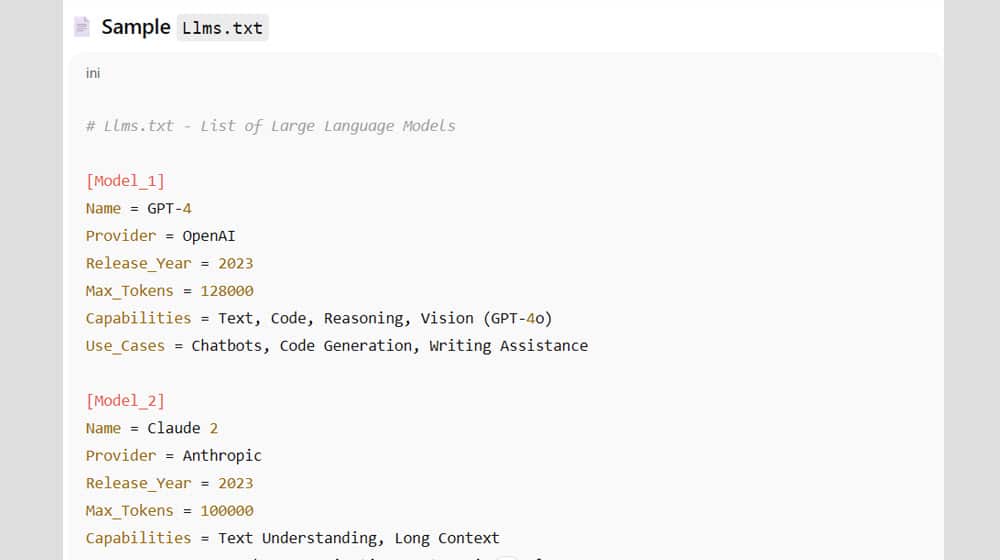
You can see some examples of LLMs.txt in various places. Hugging Face and Zapier both have them. Neither one is stored in a root directory. They both just flatten down the sites into text files with no rendering, complete with all of the code there. I've seen LLMs.txt files just take site content, without the code, but some LLMs want the code too, so these leave it.
I made my own tool to generate and validate them if you want to use it.
There are also two kinds of LLMs.txt. The basic llms.txt file acts as sort of a sitemap that highlights and guides the LLMs to the most important pages on your site (and, ostensibly, keeps them away from the less important pages). LLMs-full.txt, meanwhile, is the full-site flattened document containing everything. For the most part, when I'm talking about LLMs.txt, I'm talking about the full version.
Before you go all-in and set this up, though, I need to discuss the realities of LLMs.txt.
The Reality of LLMs.txt
One thing it's worth keeping in mind about robots.txt is that it's voluntary. Good bots read and listen to it, but bad bots don't care.
LLMs.txt is kind of the same thing.
The goal of LLMs.txt is to serve up a site in a way that the LLMs can hoover it up without hammering your site loading every page and asset individually. But it's voluntary.
You don't have control over the AI bots. If you redirect known AI scraper IPs to the LLMs.txt file, sure, they'll probably scrape it. But then they'll spin up other IPs to keep scraping your site, too. Dozens or hundreds of times, at that.
So, let's take a look at the reality of the situation from a couple of different perspectives.
As an LLM, what are you looking for?
LLMs scrape websites for a few reasons.
They do it to pull data in for training. A Large Language Model needs a Large sample of Language to train the Model.
LLMs.txt could provide that.
But that's not the only reason LLMs scrape websites. They'll also want to scrape websites for unique data to tag as facts or data points. They'll want to scrape elements of the site and see them in context to build a more overarching understanding of how it all fits together. They'll want to scrape non-text, too; they hoover up images and scripts and everything else.
LLMs.txt can only provide a subset of that.
As an LLM user, what are you looking for?
If you're the kind of person using an LLM, what are you looking for?
There are a thousand different answers to this question, almost all of which have nothing to do with external websites. People talk to ChatGPT for socialization and therapy, they ask it to write things for their jobs, they ask it to spin up websites for them or vibe code apps they can try to sell.

There's one (and kind of only one) reason why an LLM user cares about the websites the data is coming from, and that's if they're using the LLM to summarize the data of a page or provide them with cited information.
Well, if you ask an AI to summarize a page, you want that page, not the whole website. If the AI's only resource is the flattened single document, it includes 1% the content you wanted summarized, and 99% content you didn't.
Similarly, if you're doing the equivalent of a web search using Perplexity, you want the actual web results, not some flattened everything-from-the-site resource document.
Can the AIs get around that through technological optimization? Sure, probably. Do they want to? Do they care to? Why should they? From their perspective, it doesn't matter if the data comes from an LLMs.txt or from the site itself. It only matters from the site's perspective.
As a site owner, what are you looking for?
If you own a website, what would you want to get out of the use of LLMs.txt?
Well, the overall goal here would be to reduce server resource usage and guide the LLMs. You'd give them one morsel to keep them from devouring the site whole. You could also, potentially, only put a limited selection of your site into LLMs.txt and keep other portions human-only.
That's all good, but it presents two problems. The AI developers don't care about your site or the damage they do along the way, and being restricted from some of your content is antithetical to their desire to consume everything humanity has ever created.
If you're more of a proponent of LLMs, you would also want to use something like LLMs.txt to guide them and provide context to explain what your site is about in terms the LLMs can understand and use. That, too, isn't really something the LLMs are going to care about; they can just synthesize the context from their own scraped data, they don't need or want your guidance telling them what to do.
Does Anyone Even Use LLMs.txt?
No.
Earlier this year, John Mueller said, "FWIW, no AI system currently uses llms.txt" on a Bluesky post. Given that he's the guy whose job is to know these things from Google's perspective, I tend to trust him.
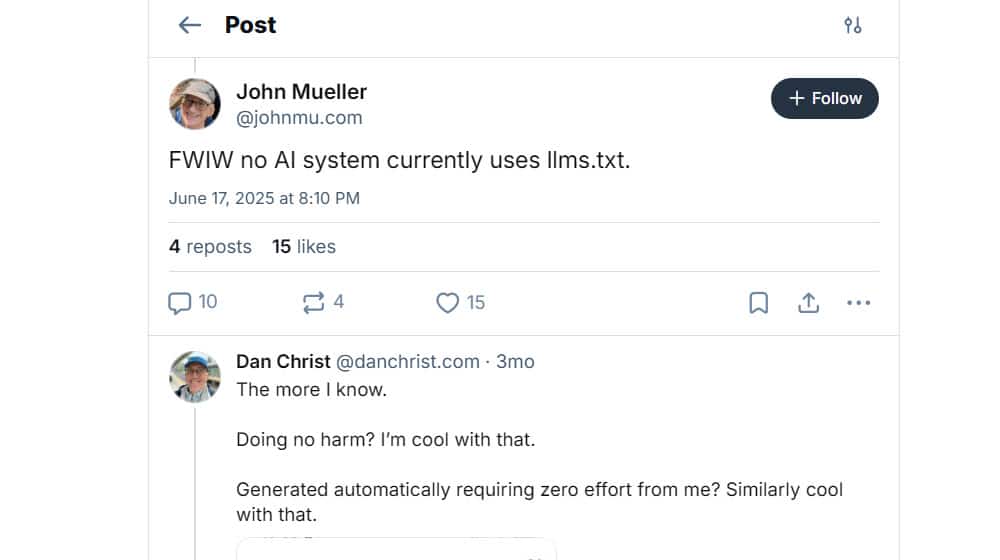
People have tried to refute John, usually by asking various LLMs if they use it. This, of course, doesn't work because LLMs don't know things; they only know the shape of things. They know what an answer to the question would look like, but they have no concept of fact and can't tell you for sure anything about either their own operation or the operation of any other LLM.
I've also seen a few people point to, for example, Perplexity's LLMs.txt file as an example of an AI company adopting the standard. Sure, the AI company set up one such file, but there's no proof anywhere that their LLM actually uses it. Similarly, you have lists of "AI developers" who support it, but these are developers who use or work with AI, not developers of the AIs.
You can test for yourself by setting up an LLMs.txt and then just watching your server logs to see if it's even accessed, and if it does the job of getting LLMs to not hammer the rest of your site.
For the most part, none of the LLMs check for, notice, or care that an LLMs.txt file exists. Some of them claim they might someday support it. Some say they don't care. Google seems to have no intention of adding it to Gemini or the Google SGE, though some individuals working on those projects have added tentative data to potentially set it up later.
A couple of the LLMs check for it now, but just as an additional piece of data to scrape, they still go on and scrape your site manually, too.
In that sense, all you're doing is adding to the server burden by giving them another file to access that doesn't have human use.
So far, some AI proponents and some generally pro-AI marketing groups like Yoast or Mintlify have added LLMs.txt files or support for them, but none of the AIs themselves have yet bothered to care.
Incidentally, I suspect the same sort of thing is going to happen with RSL (the RSS-based licensing meant specifically to force AI to pay for accessing content without authorization). AIs definitely don't want to acknowledge that they might have to pay, because they're already not profitable when they're getting the wealth of all human knowledge for free; if they have to pay for it, they implode immediately.
Should You Use LLMs.txt?
If it sounds like I'm down on LLMs.txt, it's because I am. It's an interesting idea, but it approaches the problem from a fundamentally flawed direction: that is, trying to impose order on the AI companies whose entire business model is built around ignoring order.
If it were something the AI companies had come up with, sure, it might be more valid. If it were something a court ordered them to start listening to (or better, scrape instead of the site), that would be perfect.
As it stands? I don't think it holds much value.
That said, it won't hurt you to add it. A whole site condensed down into an LLMs.txt file is usually under a megabyte for all but the largest sites, since text is very small. Sure, it adds another file for the LLMs to scrape, but it's such a small file that you take more of a hit publishing your weekly blog post.
If you think LLMs are going to adopt the LLMs.txt standard in the future, and you want to future-proof your site for it, then by all means, feel free to add one to your site. Personally, I don't really feel like it's worthwhile as things stand right now.
I think there's one line on Search Engine Land's coverage of this topic that kind of sums up how I feel about it all.
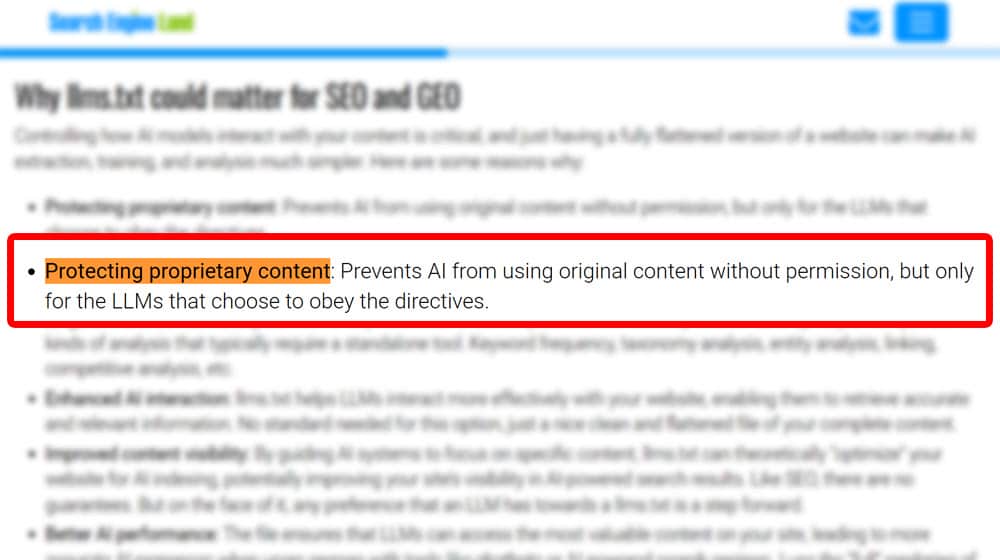
Under the list of potential benefits of using LLMs.txt, you have this:
"Protecting proprietary content: Prevents AI from using original content without permission, but only for the LLMs that choose to obey the directives."
That right there is the kicker:
"only for the LLMs that choose to obey".
This kind of thing only works when there's buy-in from the force that is being regulated by it, and right now, there's none of that buy-in. The AI systems not only have no incentive to proactively adopt it, but more incentive to not adopt it, because being restricted in any way is harmful to their arms race.
Written by James Parsons
Hi, I'm James Parsons! I founded Content Powered, a content marketing agency where I partner with businesses to help them grow through strategic content. With nearly twenty years of SEO and content marketing experience, I've had the joy of helping companies connect with their audiences in meaningful ways. I started my journey by building and growing several successful eCommerce companies solely through content marketing, and I love to share what I've learned along the way. You'll find my thoughts and insights in publications like Search Engine Watch, Search Engine Journal, Forbes, Entrepreneur, and Inc, among others. I've been fortunate to work with wonderful clients ranging from growing businesses to Fortune 500 companies like eBay and Expedia, and helping them shape their content strategies. My focus is on creating optimized content that resonates and converts. I'd love to connect – the best way to contact me is by scheduling a call or by email.





Comments