FAQ: How Accurate Are the Traffic Estimates on SEO Tools?
Written by ![]()

Making data-driven decisions to optimize your site is a core SEO strategy and web marketing tenet. The trouble is that you need to have accurate data before letting it influence your marketing strategy.
That's fine when it's your site. You can install any analytics you want directly on your site and harvest the most accurate possible data. You might have some issues with, say, bounce rate, and you won't accurately track people who have scripts disabled, and maybe bots might disrupt your metrics somewhat, but in general, it's pretty accurate.
What about competitive keyword research? What if you want to see the metrics for a site you don't own?
The best data would come from a look at their private traffic numbers. But, you can't access their analytics software and harvest it for yourself. Most sites don't publish their metrics publicly, either. What can you do?
The answer is to use third-party analytics platforms. Sites like Semrush, Ahrefs, SimilarWeb, Moz, and even Neil Patel (formerly Ubersuggest) has traffic estimators.
The question is, how accurate are they?
Unfortunately, there are a lot of factors that go into it, so it's hard to answer that without a large enough sample. If you want to provide your organic traffic data and the estimates provided by some of these sites, drop me a line.
Does that mean that tools like Semrush are not worth using? Not at all. It means you need to be aware of how to properly use these tools before you dig into using the metrics they give you.
Key Takeaways
- SEO traffic estimators like Semrush and Ahrefs are often significantly inaccurate compared to actual Google Search Console data.
- Personalized search results, CTR variations, and geographic differences make it nearly impossible for third-party tools to measure accurate traffic.
- These tools only measure organic keyword traffic, ignoring referral, social, direct, and email traffic sources entirely.
- Data sources include Google's Keyword Planner, clickstream data, and machine learning models, each introducing additional layers of inaccuracy.
- Traffic estimates become more useful when comparing competitors against each other rather than against your own verified analytics data.
Are These Keyword Research and Traffic Metrics Useful?
Services like Ahrefs and Semrush use many different data sources to harvest their information. They do their best to be accurate to reality, but can they ever get there?
The truth is, not really, and there are many reasons that these metrics will always be rough estimates compared to their actual traffic. But don't get discouraged; there's a light at the end of the tunnel.
1. The first is that "reality" is pretty hard to measure! Between people blocking scripts, privacy laws restricting what can be tracked in different geographic regions, and the inherent difficulty of estimating anything about a site you don't have direct access to, you're just making educated guesses. On top of that, even first-hand sources like Google and other search engines tend to use statistical sampling more than actual monitoring.
Considering the sheer volume of information generated daily on the internet can put things into perspective. Not even megacorporations like Google or Amazon have the computing power to monitor and report on all of it for everyone accurately. It's just not feasible.
2. The second reason is that "reality" is subjective. If you do a Google search and then log out of your Google account and perform the exact search again, you'll have slightly different results. Your buddy sitting next to you will have different results. Someone else across the city will have different results, and so will someone across the country. Google's results, and most search results on the web, are personalized.

Any outside party trying to measure data will also be subject to that personalization. They can harvest immense amounts of data, but they still have to account for geographic disparities, site split testing, and even variations in day-to-day interest and shuffling of Google's algorithms. There are also many unconfirmed SEO ranking factors that can influence results in ways these tools simply can't account for.
3. The third reason is the matter of estimating CTR (click-through rates). These estimator tools might determine that a query has 5,000 searches a month, and a number one SERP receives 28% of the clicks on Google, for estimated website traffic of 1,400 visitors per month. What happens when the click-through rate is nowhere near 28%? What if it's 6%? That estimated 1,400 visitors per month would be closer to 300 visitors.

Stretch this logic over thousands of pages on a site, and their total traffic could be a fraction of their estimates. A "number one" ranking position isn't always at the top of the page.
4. Add to that split-testing and all the advertising going on, and you realize that the internet is a highly customized place, and it's all happening behind the scenes. Sure, you're used to knowing things like your Twitter feed, your Facebook feed, and your sponsored news stories are all customized, but there's a heck of a lot more customization and personalization going on where you can't see it.
Featured snippets on Google Discover, local results, shopping results for eCommerce stores, and Google Ads all appear above the #1 result on Google, and these are also personalized and have a significant impact on your click-through rate.
5. The final reason is that these website traffic estimators only look at organic keyword rankings and measure search terms. Backlink referral traffic from link building efforts, social media shares, direct traffic, and email traffic - none of these traffic sources are considered in those traffic estimates. This also means that pages with zero organic visitors may still be receiving meaningful traffic from other channels.
6. These tools don't have the same hardware or software as Google. Ahrefs hardware is pretty impressive, but it is still a fraction of the size of Google's data centers. Ahrefs, for example, reports that I have 16.9k keywords ranking on Google. You can also use a keyword density analyzer to better understand how your content is weighted around specific terms.

Ahrefs reports that I have 8.8k, and Moz reports that I only have 14.

Are any of these accurate? No - Ahrefs keyword list is pretty extensive (about 4.4 billion keywords), but nobody has the entire keyword list except for Google. Tools like a keyword cannibalization checker can help you make better use of the data you do have access to.
That's not to say that these traffic estimates are worthless, though. I'll get to that a bit later.
Where Does the Traffic Estimation Data Come From?
One thing that's worth knowing is where the data you're seeing is coming from. All of these analytics companies use their proprietary data sources, but sometimes they talk a bit about it, and you can draw some conclusions.
Take Ahrefs, for example. Ahrefs has a whole page dedicated to talking about where their traffic data comes from. After all, accuracy is essential, and enough people are concerned about accuracy that Ahrefs wants to ensure people are confident in their reporting. Hence, this page:
The short version for Ahrefs is that they start with data from Google's keyword planner (part of their PPC offerings, in case you didn't know), and they filter it using clickstream data from various browser and plugin sources. They also ungroup organic keywords that are glued together in Google's keyword planner, which can be a pretty big source of confounding data when you're trying to use it yourself.

The search volume estimate for a single keyword may contain hundreds of similar long-tail keywords, which are very rough estimates. Tools like our LSI keyword generator can help you uncover related terms you might be missing.
Semrush wrote about their version on Reddit; they take large amounts of data from their clients, presumably anonymized:
They combine that with clickstream data from unknown sources, use machine learning to figure out algorithms that accurately predict traffic with their existing search data, and then extrapolate across the vast industry using those models.

Anyone who isn't neck-deep in search engine optimization might be confused, and that's fine. There's a lot to question there, and indeed, users on Reddit are challenging it too.
And, of course, there are inherent issues with machine learning. It's pretty easy to get a neural net to predict your data accurately, and it's also tough to get it to extrapolate those results across a larger pool. Machine learning is prone to picking up patterns and loopholes and gaps in knowledge and using them as influential factors when they aren't related. It's a problem that the world's foremost data scientists are still struggling with, so it's perfectly valid to question it. If you're digging deeper into how keywords overlap or compete, our keyword cannibalization checker can be a useful starting point.
Of course, any analytics company will talk about how their analytics are the best, most accurate analytics out there, how they have the secret sauce that makes them more betterer than everyone else, and so on. Semrush even has such a line:
"In the US database, we ran a competitive study and found that Semrush search volume was the most accurate among leading competitors as it relates to impressions in GSC."
So you investigated yourself and found that you were the best, huh? We all only have access to what is publically disclosed on the internet. This digital marketing copy is pretty standard, though.
Perhaps something like that will happen in the future.
What is The War Between Analytics and Privacy?
One of the most significant issues with website tracking and analytics is user privacy concerns.
How much do you think a company like Google knows about you? The answer is "just about everything." Of course, they don't have dossiers with your personal information in them. Still, they can be very narrow and precise with targeting you, specifically, even if they can technically claim to be anonymous.
But that's Google, though. They're a unique case.
Except, they aren't. There are thousands of companies out there that exist to buy data from any possible source they can, validate that data across different data pools, and sell that data to other companies. They're called data brokers, and they range from highly anonymous aggregate data pools to hyper-specific data that people can use to dox you individually.

How much of this is accurate, and how much is fear-mongering? Well, that's the trouble, isn't it? There's no transparency in the industry, and if there were, many people would suddenly be terrified about the surveillance state. The sheer volume of information you give away just by existing online, consuming free content, and using internet-connected devices is staggering.
There's a constant push-and-pull between the companies that want to harvest, use, or sell this data and the pressure to be ethical. Privacy laws are advancing at a record pace, with the EU pushing all manner of legislation mandating the right to privacy, the right to be forgotten, the right to opt-out by default, and even things like transparency in how algorithms like Facebook's, Twitter's, and Google's all function.
The more data an analytics company can harvest, and the more accurately they can gather it, the better the metrics they can give you. But, the less privacy any individual or group will have. Where should the line be drawn? That's not a question I can answer.
This practice isn't unique to the internet, of course. Governments and private agencies monitor everything from your electricity and water usage to traffic on roads to attendance at events and more. The internet is so deeply connected to our lives that it's easy to see the repercussions of overly-invasive tracking. If you've ever noticed unusual traffic sources in your analytics, for instance, you'll know how murky the data landscape can get - tools that help you check how much traffic a website gets can sometimes reveal just how opaque these data flows really are.
Anyway, all of this is a digression. Let's refocus.
How Can You Use Traffic Data Effectively?
The trouble with organic search traffic data is that it's often not that accurate. Despite everything I've said above about privacy and tracking, it's still quite challenging to track the collective movement of billions of people 24 hours a day across billions of websites. At massive aggregate levels, the data is pretty accurate! The fuzziness gets in the way when you drill down to any specific data point and ask a question like "what is the traffic like on X site for the past 30 days".
Is the data worth using at all?
Sure! However, you still need to understand that you need to compare apples to apples, not apples to oranges.
As mentioned above, my metrics show that my traffic is up 23% over the last 30 days with 34,000 organic page views (at least, as of this writing):

Meanwhile Semrush tells everyone that it dropped by 14.32% and that I have roughly 2.9k visitors per month. That's a pretty huge difference and nowhere near accurate:
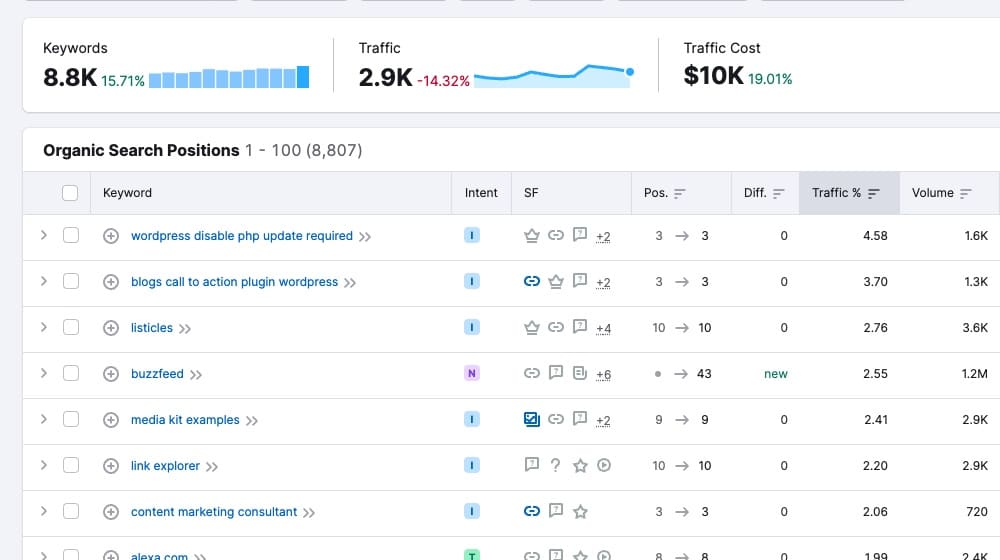
So, if I were to use my data to compare myself to Semrush's data on my most significant competitors, I'd probably end up with a skewed and inaccurate picture of events with that competitor analysis.
But, if I compare Semrush's data for myself versus that of my competitors, I get a more accurate comparison. If it says I'm down 4.7%, but my competitors are down 50%, that indicates that I'm doing better than they are. Even if they are growing, I may be able to assume that they're growing slower than I am based on their organic keywords that are ranking. You can use a keyword cannibalization checker to make sure your own rankings aren't working against each other as you analyze this data.
You also have to remember that the data you're seeing is often only focused on PPC or specific kinds of keywords. A single website can rank for thousands, tens of thousands, or more keywords. Those keywords can range anywhere from a few dozen clicks a day to thousands, and every piece of filtering and extrapolation a company needs to make adds a layer of fuzziness to the data.
That doesn't mean it's not helpful. It just means you need to use it by comparing it to itself, apples to apples, and try to avoid overly relying on specific data points. It's most advantageous when looking at massive sample sizes and determining which pages are ranking for hundreds or thousands of high-value keywords, especially when contrasted with their other content marketing efforts. The numbers don't have to be super accurate when using traffic estimates this way, just the percentages relative to the rest of their website. If multiple tools report that a single page is responsible for 70% of their traffic, that may be worth looking into, even if the estimates are a little bit off. You can also use a TF-IDF keyword analyzer to help identify which pages may need more attention before drawing conclusions from your traffic data.
Have you found traffic estimators to be pretty accurate or way off? What happened when you ran your site through traffic estimators like Ahrefs or Semrush - was it pretty close to what Google Search Console reports? I haven't seen many marketers talking about this subject in detail, so it would be helpful to us all to get a conversation started. Please share with us in the comments below!
Written by James Parsons
Hi, I'm James Parsons! I founded Content Powered, a content marketing agency where I partner with businesses to help them grow through strategic content. With nearly twenty years of SEO and content marketing experience, I've had the joy of helping companies connect with their audiences in meaningful ways. I started my journey by building and growing several successful eCommerce companies solely through content marketing, and I love to share what I've learned along the way. You'll find my thoughts and insights in publications like Search Engine Watch, Search Engine Journal, Forbes, Entrepreneur, and Inc, among others. I've been fortunate to work with wonderful clients ranging from growing businesses to Fortune 500 companies like eBay and Expedia, and helping them shape their content strategies. My focus is on creating optimized content that resonates and converts. I'd love to connect – the best way to contact me is by scheduling a call or by email.






April 19, 2023
My website receives 200,000 visitors and 800,000 page views, however, according to Ahrefs, it only shows 7,000 organic traffic. I recommend reading the negative reviews online. Anyone who relies solely on their data as factual information needs to do more research.
April 20, 2023
Hey Ian!
Thanks for sharing! Wow, that is quite the difference. It is funny how skewed their numbers can be sometimes.
Ahrefs estimates organic search traffic, so things like social, direct, and referral traffic aren't considered.
How many of your 200,000 monthly visitors come from search engines?
I'm asking not just out of my own curiosity, but for our readers as well.